Biography
I’m Rohit K Bharadwaj, a first year PhD student at the University of Edinburgh, working under the supervision of Dr. Hakan Bilen.
I have experience working in Android Development, Deep Learning, and on various Computer Vision, and NLP research projects.
I’m motivated to contribute towards the development of AI, and more specifically Computer Vision technologies, so that they can be deployed more widely in the real world, and help people in their day-to-day lives.
I’ve mostly worked on Biometrics, Topic Modelling, Generative Models (GANs and Diffusion), Object Detection, and Large Language Models (LLMs).
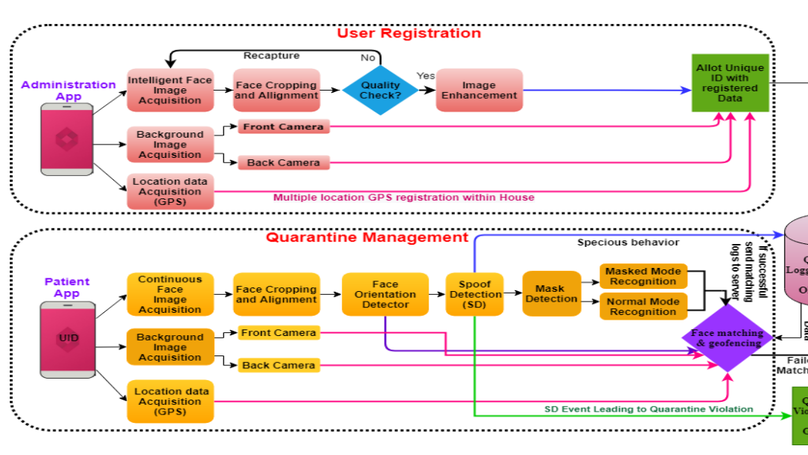
I’m currently working at the intersection of computer vision and privacy to develop models that can generate images with privacy guarantees.
News:
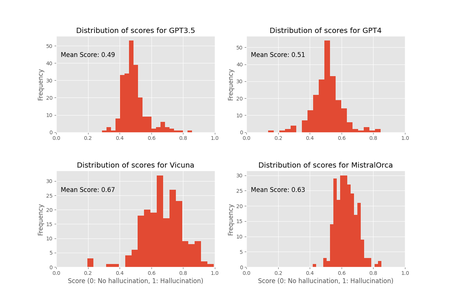
- My work from my Master’s thesis was accepted for publication at the WACV 2025 Conference, to be held in Tucson, Arizona!
- Started my PhD at the School of Informatics in the University of Edinburgh on September 2024.
- Completed all the course requirements at MBZUAI with a CGPA of 3.90/4.00.
Download my resumé.
- Generative Models
- Computer Vision
- Representation Learning
-
PhD Informatics, 2024 - 2028
University of Edinburgh
-
MSc Machine Learning, 2022 - 2024
MBZUAI
-
B.E Computer Science, 2018 - 2022
BITS Pilani
-
MSc Mathematics, 2017 - 2022
BITS Pilani
Experience
- Worked on improving functionality of existing NodeJS based APIs, which were being used in the company’s internal dashboard. I was also responsible for the front-end changes and writing of Unit Tests (UTs) for the APIs.
- Was also able to convert my internship into a full-time offer.
- Created custom OpenAPI schema validation rules. These custom rules allows much stricter schema validation.
- Created an automated python script to extract out 4 pipeline data (UT, Lint, Type Errors, Circular Dependencies) from each of the 25 microservices.
- Integrated In-Memory MongoDB with Jest, which eliminates the need to mock DB calls for UTs.
Tech stack: NodeJS, Typescript, OpenAPI, MongoDB, Jest, MySQL, Grafana, Kibana, Microservices and Distributed Systems.
- Explored and implemented topic modelling algorithms like Word2Vec, LDA, and Lda2Vec using Gensim and PyTorch in a given knowledge domain of water resources management. The experiments were conducted on 28k full-text documents and 88k abstracts over 7 academic journals.
- Generated word clouds and interactive HTML visualizations showing the inter-topic distance map using PyLDAVis.
- Computed and compared topics generated by each model [LDA and Lda2Vec], dataset [abstract and full-text], and pre- processing methods [WordNet Lemmatizer, Noun + Verb, and Noun + Verb + Adjective] over each of the 7 journals using jaccard distance to plot and visualize the correlation heatmaps. [7 journals × 2 datasets × 6C2 = 210 comparisons]
Responsibilities:
- Developed the Student’s Union App
- Guiding and Leading the App Development Team
Worked directly under Dr. S. Ramachandran, Senior Principal Scientist, Council of Scientific and Industrial Research - Institute of Genomics and Integrative Biology, Delhi, India.
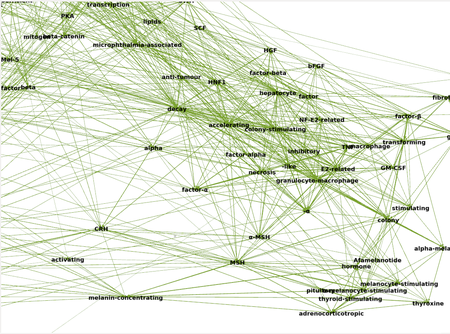
- Project was on clustering and visualizing similar medical terms present in biomedical literature. Scrapped over 7074 abstracts on the topic of “Vitiligo” from PubMed. Handled entire end-to-end pipeline of data acquisition, data pre- processing, model training, and visualization of results.
- The data pre-processing was handled using regular expressions, stop-word removal, and lemmatisation. Bi-grams from the data were obtained using Gensim, and the common data pre-processing stages were implemented using NLTK.
- GloVe model was then trained on the dataset to obtain vector embeddings of the words and bi-grams. Visualization of the embeddings was done using Gephi. Thus, the vocabulary terms were visualised in the form of a weighted graph, where the weight of the edges between two terms was equal to the cosine similarity of their respective embeddings. Project on Github.