Abstract
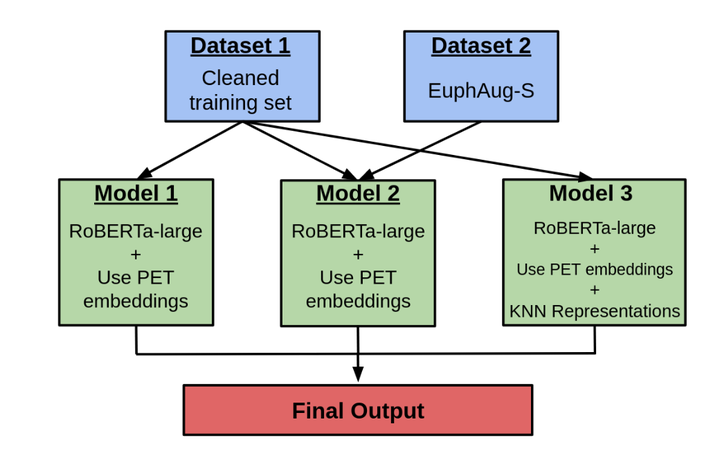
We introduce EUREKA, an ensemble-based approach for performing automatic euphemism detection. We (1) identify and correct potentially mislabelled rows in the dataset, (2) curate an expanded corpus called EuphAug, (3) leverage model representations of Potentially Euphemistic Terms (PETs), and (4) explore using representations of semantically close sentences to aid in classification. Using our augmented dataset and kNN-based methods, EUREKA was able to achieve state-of-the-art results on the public leaderboard of the Euphemism Detection Shared Task, ranking first with a macro F1 score of 0.881.
Type
Publication
EMNLP 2022 Figurative Language Workshop; first place for Euphemism Detection Shared Task
Rohit K Bharadwaj
PhD Informatics
Interested in Computer Vision, Privacy, and Representation Learning.