Cooperative Foundational Models
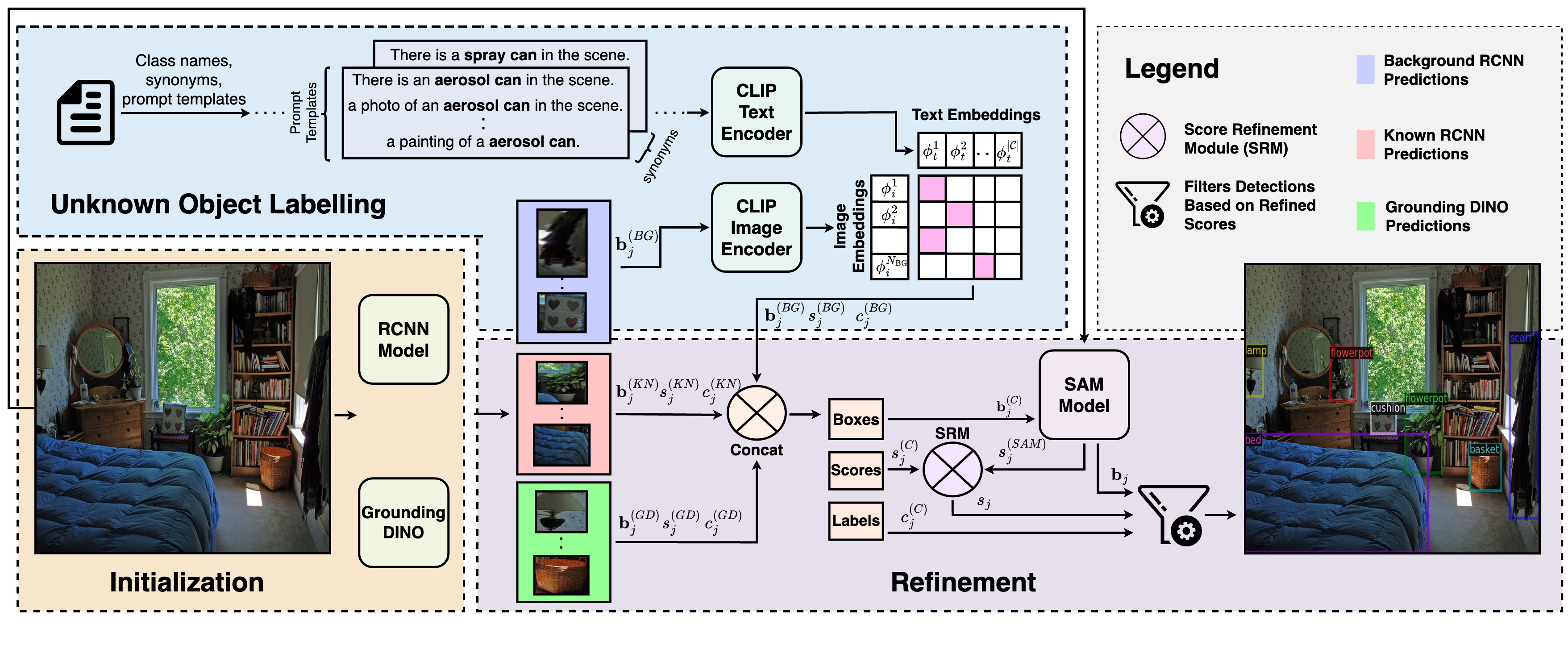
Our proposed cooperative mechanism integrates pre-trained foundational models such as CLIP, SAM, and GDINO with a Mask-RCNN model in order to identify and semantically label both known and novel objects. These foundational model interacts using different components including Initialization, Unknown Object Labelling, and Refinement to refine and categorize objects. We establish state-of-the-art (SOTA) results in novel object detection on LVIS, and open-vocabulary detection benchmark on COCO.